Develop a Model-Agnostic Interpretable Data-driven suRRogate in R with maidrr
Roel Henckaerts
Source:vignettes/maidrr.Rmd
maidrr.Rmdlibrary(maidrr)
MTPL datasets included in maidrr
The maidrr package contains two motor third party liability (MTPL) insurance portfolios, one from Belgium (BE) and one from France (FR). Both will be used to illustrate the use of maidrr, so let’s have a quick look at them:
data('mtpl_be') ; str(mtpl_be, give.attr = FALSE) #> 'data.frame': 163210 obs. of 13 variables: #> $ id : int 1 2 3 4 5 6 7 8 9 10 ... #> $ expo : num 1 1 1 1 0.0466 ... #> $ nclaims : int 1 0 0 0 1 0 1 0 0 1 ... #> $ coverage: Ord.factor w/ 3 levels "TPL"<"TPL+"<"TPL++": 1 2 1 1 1 1 3 1 2 3 ... #> $ ageph : int 50 64 60 77 28 26 26 58 43 70 ... #> $ sex : Factor w/ 2 levels "female","male": 2 1 2 2 1 2 2 1 2 2 ... #> $ bm : int 5 5 0 0 9 11 11 11 3 0 ... #> $ power : int 77 66 70 57 70 70 55 47 65 76 ... #> $ agec : int 12 3 10 15 7 12 8 14 6 2 ... #> $ fuel : Factor w/ 2 levels "gasoline","diesel": 1 1 2 1 1 1 1 1 1 1 ... #> $ use : Factor w/ 2 levels "private","work": 1 1 1 1 1 1 1 1 1 1 ... #> $ fleet : Factor w/ 2 levels "no","yes": 1 1 1 1 1 1 1 1 1 1 ... #> $ postcode: Factor w/ 80 levels "10","11","12",..: 1 1 1 1 1 1 1 1 1 1 ... data('mtpl_fr') ; str(mtpl_fr, give.attr = FALSE) #> 'data.frame': 668892 obs. of 11 variables: #> $ id : int 139 190 414 424 463 606 622 811 830 975 ... #> $ nclaims: num 1 1 1 2 1 1 1 1 1 1 ... #> $ expo : num 0.75 0.14 0.14 0.62 0.31 0.84 0.75 0.76 0.68 0.73 ... #> $ power : Ord.factor w/ 12 levels "4"<"5"<"6"<"7"<..: 4 9 1 7 2 7 2 2 1 6 ... #> $ agec : int 1 5 0 0 0 6 0 0 10 0 ... #> $ ageph : int 61 50 36 51 45 54 34 44 24 60 ... #> $ bm : int 50 60 85 100 50 50 64 50 105 50 ... #> $ brand : Factor w/ 11 levels "B1","B10","B11",..: 4 4 4 4 4 4 4 4 1 4 ... #> $ fuel : Factor w/ 2 levels "diesel","gasoline": 2 1 2 2 2 1 2 2 2 2 ... #> $ popdens: int 27000 56 4792 27000 12 583 1565 3317 3064 570 ... #> $ region : Factor w/ 22 levels "R11","R21","R22",..: 1 6 1 1 16 21 8 21 1 21 ...
The details on all the features included in the BE and FR portfolio are available in the package documentation. These can be retrieved via ?maidrr::mtpl_be and ?maidrr::mtpl_fr for the BE and FR portfolio respectively.
Black box algorithm to start from
A Poisson GBM is trained on each MTPL portfolio in order to model and predict the claim frequency, i.e., the number of claims filed by a policyholder. Note that the tuning parameter values are chosen rather arbitrarily as the tuning of an optimal black box algorithm is not the purpose of this vignette. The goal of maidrr is to obtain an interpretable surrogate model that approximates your black box as closely as possible. Let’s get started!
library(gbm) set.seed(54321) gbm_be <- gbm(nclaims ~ offset(log(expo)) + ageph + power + bm + agec + coverage + fuel + sex + fleet + use, data = mtpl_be, distribution = 'poisson', shrinkage = 0.01, n.trees = 500, interaction.depth = 3) gbm_fr <- gbm(nclaims ~ offset(log(expo)) + ageph + power + bm + agec + fuel + brand + region, data = mtpl_fr, distribution = 'poisson', shrinkage = 0.01, n.trees = 500, interaction.depth = 3)
Workflow of the maidrr procedure
This section describes the four main functions in maidrr that facilitate the workflow from black box to surrogate:
-
insights: obtain insights from a black box model in the form of partial dependence (PD) feature effects. -
segmentation: use PDs to group feature values/levels and segment observations in a data-driven way. -
surrogate: fit a surrogate generalized linear model (GLM) with factor features to the segmented data. -
explain: explain the prediction of a surrogate GLM via the contribution of all features (and interactions).
These operations are designed in a way that allows for piping via %>% from magrittr to create a neat workflow: bb_fit %>% insights(...) %>% segmentation(...) %>% surrogate(...) %>% explain(...)
Insights from the black box
Call insights(mfit, vars, data, interactions = 'user', hcut = 0.75, pred_fun = NULL, fx_in = NULL, ncores = -1) with arguments:
-
mfit: fitted model object (e.g., a “gbm” or “randomForest” object) to get insights on. -
vars: character vector specifying the features of which you want to get a better understanding. -
data: data frame containing the original training data. -
interactions: string specifying how to deal with interaction effects (only two-way interactions allowed).-
"user": specify the two-way interactions yourself invarsas the string"var1_var2". For example, to obtain the interaction effect between the age of the policyholder and power of the car, specify the following three components invars:"ageph","power"and"ageph_power". -
"auto": automatic selection of the most important two-way interactions, determined byhcut.
-
-
hcut: numeric in the range [0,1] specifying the cut-off value for the normalized cumulative H-statistic over all two-way interactions between the features invars. In a nutshell: 1) Friedman’s H-statistic, measuring interaction strength, is calculated for all two-way interactions between the features invars. 2) Interactions are ordered from most to least important and the normalized cumulative sum of the H-statistic is calculated. 3) The minimal set of interactions which exceeds the value ofhcutis retained in the output.-
hcut = 0: only retain the single most important interaction. -
hcut = 1: retain all possible two-way interactions.
-
-
pred_fun: optional prediction function for the model inmfitto calculate feature effects, which should be of the formatfunction(object, newdata) mean(predict(object, newdata, ...)). See the argumentpred.funin thepdp::partialfunction, on whichmaidrrrelies to calculate model insights. This function allows to calculate effects for model classes which are not supported bypdp::partial. -
fx_in: optional named list of data frames containing feature effects for features invarsthat are already calculated beforehand, to avoid having to calculate these again. A possible use case is to supply the main effects such that only the interaction effects still need to be calculated. Precalculated interactions are ignored wheninteractions = "auto", but can be supplied wheninteractions = "user". In case of the latter, it is important to make sure that you supply the pure interaction effects (more on this later). -
ncores: integer specifying the number of cores to use. The defaultncores = -1uses all the available physical cores (not threads).
To illustrate the use of the argument pred_fun, we define the following function for our GBMs:
gbm_fun <- function(object, newdata) mean(predict(object, newdata, n.trees = object$n.trees, type = 'response'))
For the FR portfolio, we ask for the effects on all features in the GBM and one user-specified interaction:
fx_vars_fr <- gbm_fr %>% insights(vars = c(gbm_fr$var.names, 'power_fuel'), data = mtpl_fr, interactions = 'user', pred_fun = gbm_fun)
For the BE portfolio, we ask for the effects on all features in the GBM and the auto-selected interactions:
fx_vars_be <- gbm_be %>% insights(vars = gbm_be$var.names, data = mtpl_be, interactions = 'auto', hcut = 0.75, pred_fun = gbm_fun)
The output is a named list of tibble objects containing the effects, one for each feature and interaction:
class(fx_vars_be) #> [1] "list" names(fx_vars_be) #> [1] "ageph" "power" "bm" "agec" "coverage" #> [6] "fuel" "sex" "fleet" "use" "ageph_bm" #> [11] "power_bm" "bm_agec" "ageph_power" "power_agec"
The tibble for a main effect has 3 columns with standardized names x, y, w containing the feature value, the effect and the number of observations counts in data respectively:
fx_vars_be[['ageph']] #> # A tibble: 78 x 3 #> x y w #> <int> <dbl> <dbl> #> 1 18 0.184 16 #> 2 19 0.181 116 #> 3 20 0.180 393 #> 4 21 0.173 700 #> 5 22 0.171 952 #> 6 23 0.170 1379 #> 7 24 0.169 2028 #> 8 25 0.168 2672 #> 9 26 0.165 2941 #> 10 27 0.158 3130 #> # … with 68 more rows
The tibble for an interaction effect has 4 columns with standardized names x1, x2, y, w containing the feature values, the effect and the number of observations counts in data respectively:
fx_vars_be[['bm_agec']] #> # A tibble: 1,127 x 4 #> x1 x2 y w #> <int> <int> <dbl> <dbl> #> 1 0 0 0.00942 85 #> 2 0 1 0.00708 3356 #> 3 0 2 0.00942 5509 #> 4 0 3 0.00942 5024 #> 5 0 4 0.00836 5065 #> 6 0 5 0.00834 4996 #> 7 0 6 0.00770 5795 #> 8 0 7 0.00687 5283 #> 9 0 8 0.00656 5321 #> 10 0 9 0.00633 4624 #> # … with 1,117 more rows
Notice the difference in the scale of the feature effect, contained in column y, for a main and interaction effect. This comes from the fact that the interaction effects are calculated as pure interactions by subtracting both 1D effects from the 2D effect. Therefore, the main effects will be centered around the observed claim frequency, which equals to 0.1392 for the BE portfolio, while the interaction effects are centered around zero:
unlist(lapply(fx_vars_be, function(fx) weighted.mean(fx$y, fx$w))) #> ageph power bm agec coverage #> 0.1391378818 0.1413828447 0.1392205403 0.1410044538 0.1407400071 #> fuel sex fleet use ageph_bm #> 0.1395687496 0.1407080804 0.1404085487 0.1408609926 0.0047011084 #> power_bm bm_agec ageph_power power_agec #> -0.0077431629 0.0075745816 0.0002420642 0.0014502535
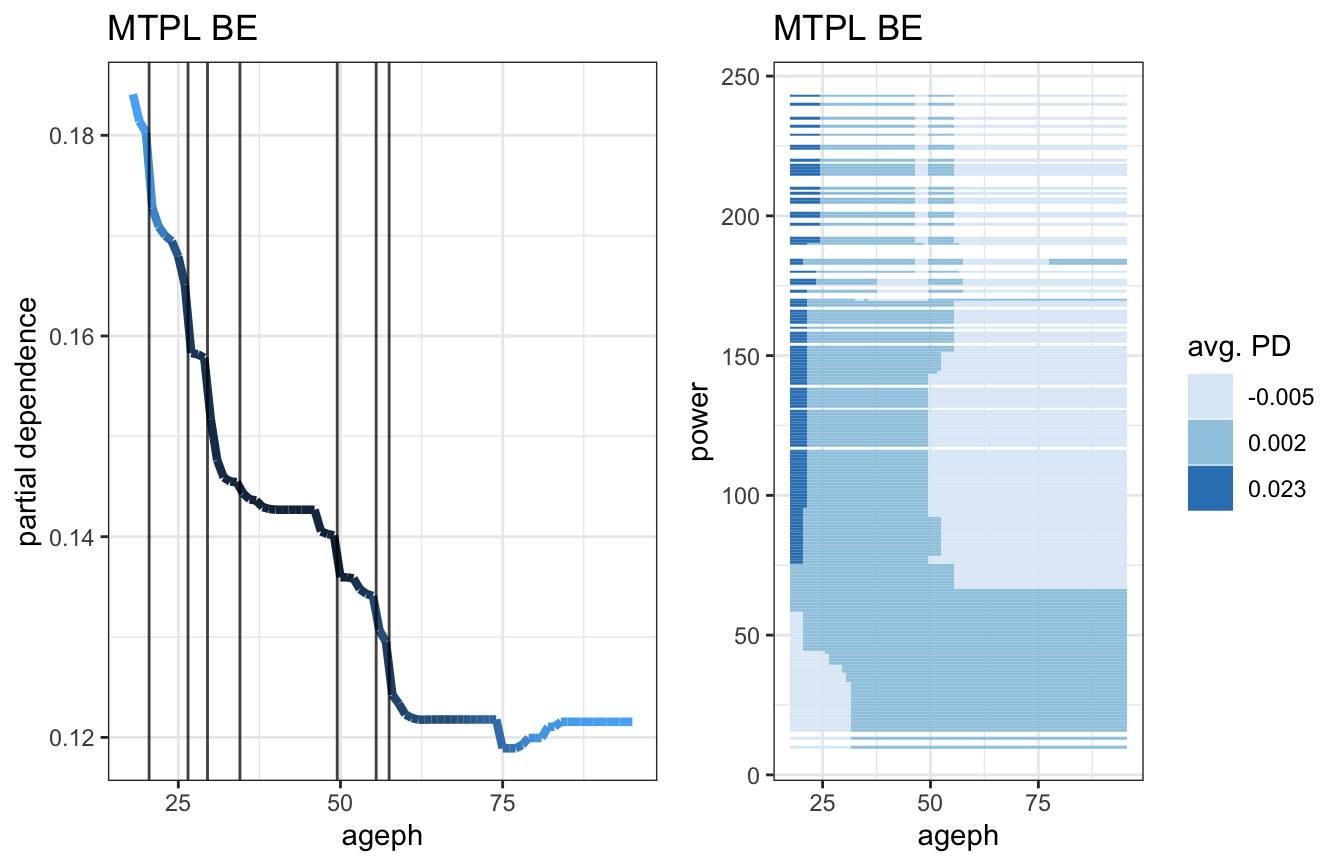
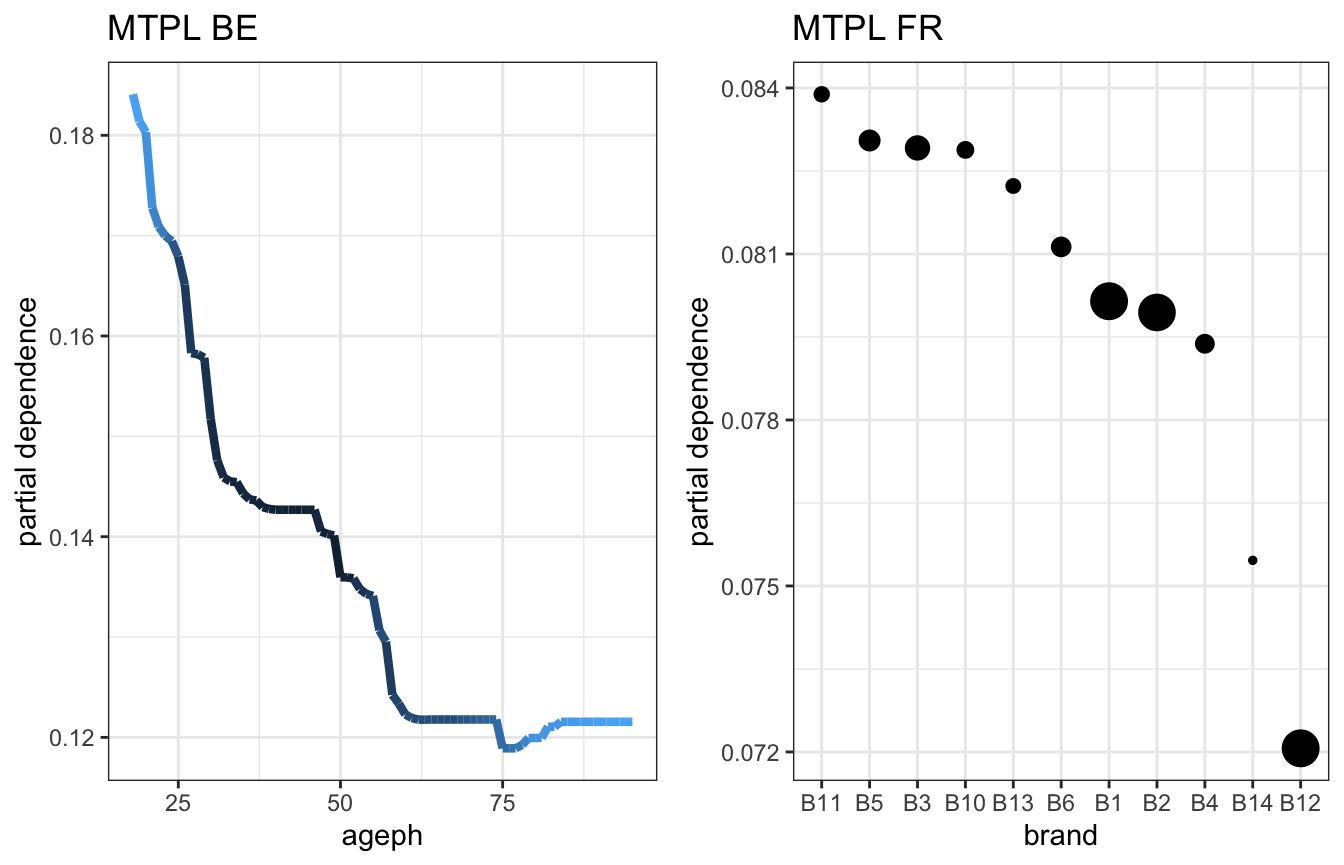
The function maidrr::plot_pd can be used to visualize the effects. This is illustrated for a continuous feature in the BE portfolio and a categorical feature in the FR portfolio, where darker colours or larger dots indicate higher observation counts for those feature values:
gridExtra::grid.arrange(fx_vars_be[['ageph']] %>% plot_pd + ggtitle('MTPL BE'), fx_vars_fr[['brand']] %>% plot_pd + ggtitle('MTPL FR'), ncol = 2)
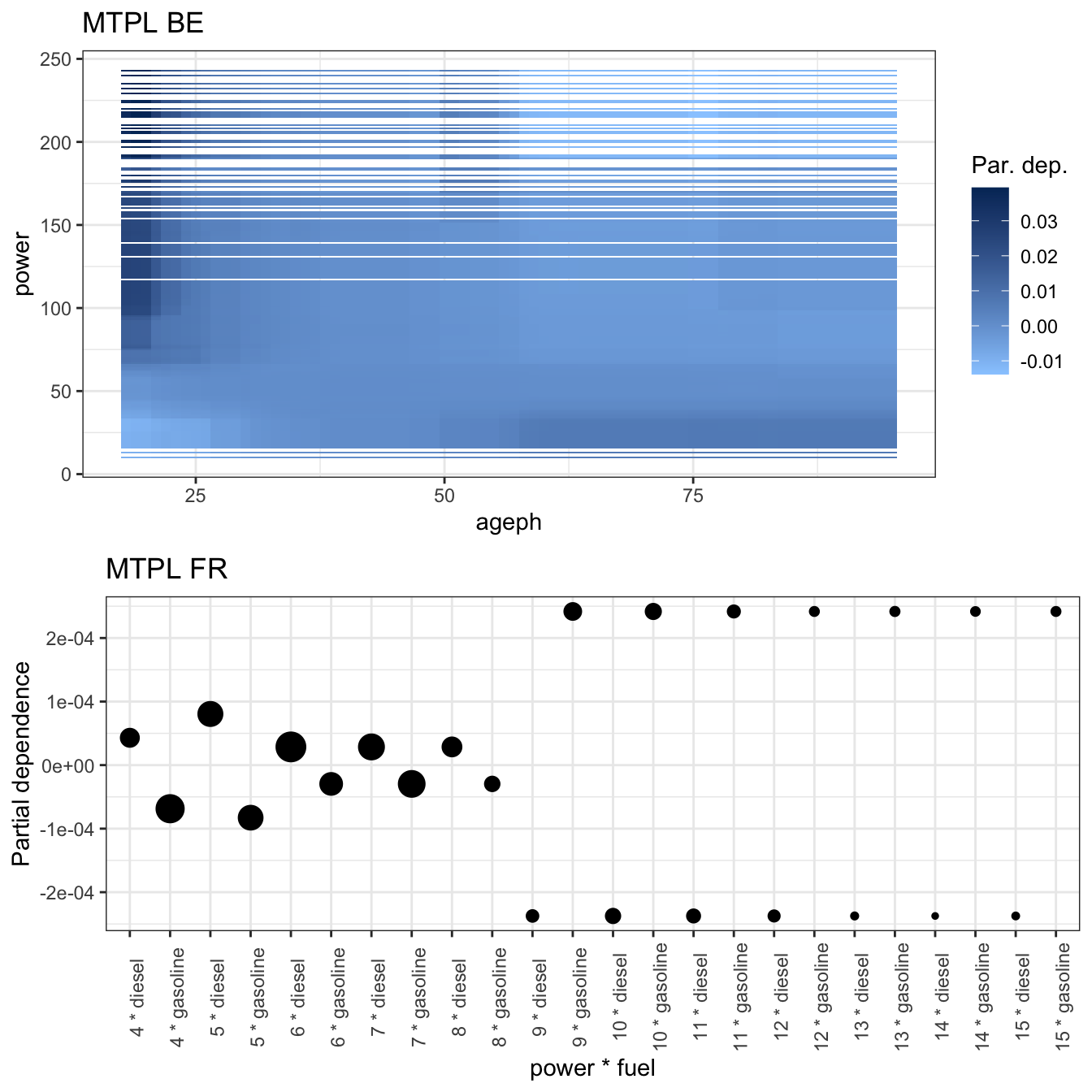
The function maidrr::plot_pd can also be used to visualize the interactions. This is illustrated for two continuous features in the BE portfolio and two categorical features in the FR portfolio. It is important to understand that these represent corrections on the main effects of those features. So young policyholders driving a high powered car receive an extra penalty on top of their main effects in the BE portfolio. In the FR portfolio one can conclude that for low powered cars diesel is more risky than gasoline, but this behaviour reverses as of power level 7 and the difference becomes even bigger as of power level 9.
gridExtra::grid.arrange(fx_vars_be[['ageph_power']] %>% plot_pd + ggtitle('MTPL BE'), fx_vars_fr[['power_fuel']] %>% plot_pd + ggtitle('MTPL FR'), ncol = 1)
The goal of the maidrr procedure is to group values/levels within a feature which are showing similar behaviour. Regions where the effect is quite stable can be grouped together, for example:
- the age ranges 35-45 and 60-80 in the BE portfolio,
- the brands B5, B3 and B10 in the FR portfolio,
- ages above 30 combined with power below 170 in the BE portfolio,
- power levels above 8 with the fuel types in the FR portfolio.
Performing such a grouping in an optimal, automatic and data-driven way is the goal of maidrr, stay tuned!
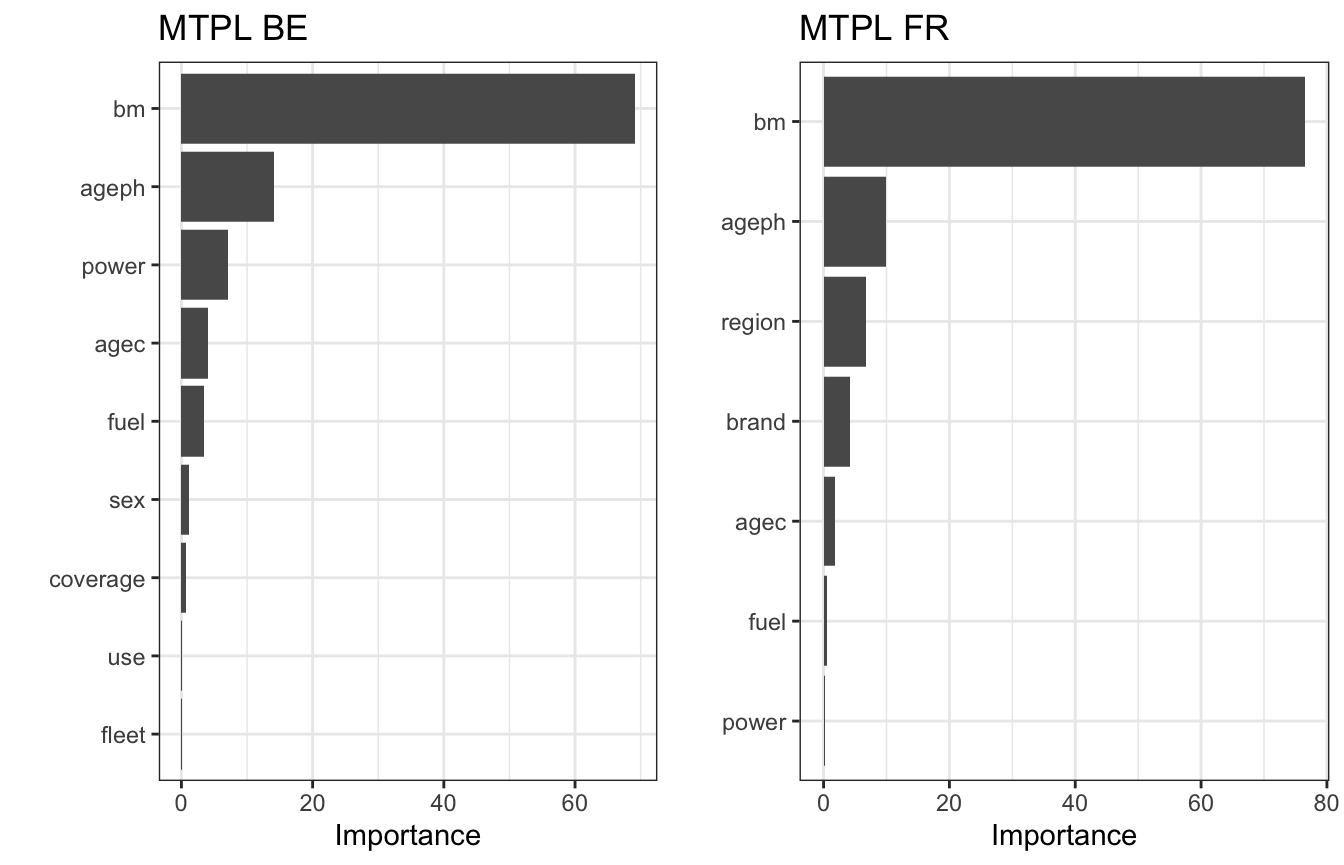
Note on variable selection: In the above examples we simply used all the features from the GBM (via $var.names on the gbm object). You might want to exclude unimportant features from your analysis to save computation time when many features are used in your black box model. The functions maidrr::get_vi and maidrr::plot_vi allow to obtain some insights on the important features in the black box. The former calculates variable importance scores for all features in the model (tibble), while the latter plots the results (ggplot). These functions can be used to determine which features to supply to the vars argument in insights.
gridExtra::grid.arrange(gbm_be %>% get_vi %>% plot_vi + ggtitle('MTPL BE'), gbm_fr %>% get_vi %>% plot_vi + ggtitle('MTPL FR'), ncol = 2)
Helper functions
The function insights streamlines the exploration process by making use of several maidrr helper functions:
-
get_pd: calculates the partial dependence (PD) effect for a specific feature (1D) or pair of features (2D). -
get_grid: determines the grid on which to evaluate the PD effect (based on the observed data values). -
interaction_pd: computes the pure interaction effect by subtracting both 1D PDs from the 2D PD. -
interaction_strength: calculates Friedman’s H-statistic for the interaction strength of two features.
These functions can be used on a stand-alone basis to perform your own tailored analysis. Details on the use of these functions and input requirements are available in the documentation of maidrr.
Segmantation of the data
Call segmentation(fx_vars, data, type, values, max_ngrps = 15) with arguments:
-
fx_vars: list of data frames containing the feature effects, preferably the output ofmaidrr::insights. -
data: data frame containing the original training data. -
type: string specifying the type of segmentation to perform. There are two options:-
"ngroups": the number of groups to use for grouping the features. -
"lambdas": the optimal number of groups are determined by the penalized loss (formula below).
-
-
values: numeric value or named numeric vector with the values forngroupsoflambdas.- numeric value: same value is used for all features in
fx_vars. - named numeric vector: feature-specific values, must satisfy
length(values) == length(fx_vars)andnames(values)must be the same as the comment attributes of the effects infx_varsas detemrined byunlist(lapply(fx_vars, comment)).
- numeric value: same value is used for all features in
-
max_ngrps: integer specifying the maximum number of groups that each feature’s values/levels are allowed to be grouped into. Only used when determinining the optimal number of groups viatype = 'lambdas'.
For any feature, let n be the unique number of observed levels/values in the data and y the calculated effect for each level/value. When the feature is split in k groups, let g represent the average value of y within the groups. A penalized loss function is defined as follows: \[ \frac{1}{n} \sum_{i=1}^{n} \left( y_i - g_i \right)^2 + \lambda \log(k) \,. \] The first part measures how well the effect y is approximated by the grouped variant g in the form of a mean squared error over all levels/values of the feature. The second part measures the complexity of the grouping by means of the common logarithm of the number of groups k for the feature. The penalty parameter \(\lambda\) acts as a bias-variance trade-off. A low value will allow a lot of groups, resulting in an accurate approximation of the effect. A high value will enforce using fewer groups, resulting in a coarse approximation of the effect. For a specified value of \(\lambda\), the optimal number of groups k follows by minimizing the penalized loss function. The grouping in maidrr is done via the Ckmeans.1d.dp package.
We segment the BE portfolio by specifying feature-specific number of groups. The grouped features are added to the data with a trailing underscore in their column name:
gr_data_be <- fx_vars_be %>% segmentation(data = mtpl_be, type = 'ngroups', values = setNames(c(7, 4, 9, 3, 2, 2, 2, 1, 1, 2, 3, 4, 2, 3), unlist(lapply(fx_vars_be, comment)))) head(gr_data_be) #> id expo nclaims coverage ageph sex bm power agec fuel use #> 1 1 1.00000000 1 TPL 50 male 5 77 12 gasoline private #> 2 2 1.00000000 0 TPL+ 64 female 5 66 3 gasoline private #> 3 3 1.00000000 0 TPL 60 male 0 70 10 diesel private #> 4 4 1.00000000 0 TPL 77 male 0 57 15 gasoline private #> 5 5 0.04657534 1 TPL 28 female 9 70 7 gasoline private #> 6 6 1.00000000 0 TPL 26 male 11 70 12 gasoline private #> fleet postcode ageph_ power_ bm_ agec_ coverage_ fuel_ #> 1 no 10 [50, 57] [45, 170] [3, 6] [0, 16] [1, 1] {gasoline} #> 2 no 10 [58, 95] [45, 170] [3, 6] [0, 16] [2, 3] {gasoline} #> 3 no 10 [58, 95] [45, 170] [0, 1] [0, 16] [1, 1] {diesel} #> 4 no 10 [58, 95] [45, 170] [0, 1] [0, 16] [1, 1] {gasoline} #> 5 no 10 [27, 29] [45, 170] [7, 9] [0, 16] [1, 1] {gasoline} #> 6 no 10 [21, 26] [45, 170] [11, 13] [0, 16] [1, 1] {gasoline} #> sex_ fleet_ use_ ageph_bm_ power_bm_ bm_agec_ ageph_power_ #> 1 {male} {no, yes} {private, work} 2 2 3 1 #> 2 {female} {no, yes} {private, work} 2 2 3 1 #> 3 {male} {no, yes} {private, work} 2 1 3 1 #> 4 {male} {no, yes} {private, work} 2 2 3 1 #> 5 {female} {no, yes} {private, work} 2 2 3 1 #> 6 {male} {no, yes} {private, work} 2 2 4 1 #> power_agec_ #> 1 3 #> 2 3 #> 3 3 #> 4 3 #> 5 3 #> 6 3 gr_data_be %>% dplyr::select(dplyr::ends_with('_')) %>% dplyr::summarise_all(dplyr::n_distinct) #> ageph_ power_ bm_ agec_ coverage_ fuel_ sex_ fleet_ use_ ageph_bm_ power_bm_ #> 1 7 4 9 3 2 2 2 1 1 2 3 #> bm_agec_ ageph_power_ power_agec_ #> 1 4 2 3
We segment the FR portfolio by specifying a single \(\lambda\) value for all features and the interaction:
gr_data_fr <- fx_vars_fr %>% segmentation(data = mtpl_fr, type = 'lambdas', values = 0.000001) gr_data_fr %>% dplyr::select(dplyr::ends_with('_')) %>% dplyr::summarise_all(dplyr::n_distinct) #> ageph_ power_ bm_ agec_ fuel_ brand_ region_ power_fuel_ #> 1 9 2 15 3 2 6 8 1
It is possible to use maidrr::plot_pd with maidrr::group_pd to get an idea of the actual grouping of features:
gridExtra::grid.arrange(fx_vars_be[['ageph']] %>% group_pd(ngroups = 7) %>% plot_pd + ggtitle('MTPL BE'), fx_vars_fr[['brand']] %>% group_pd(ngroups = 5) %>% plot_pd + ggtitle('MTPL FR'), ncol = 2)
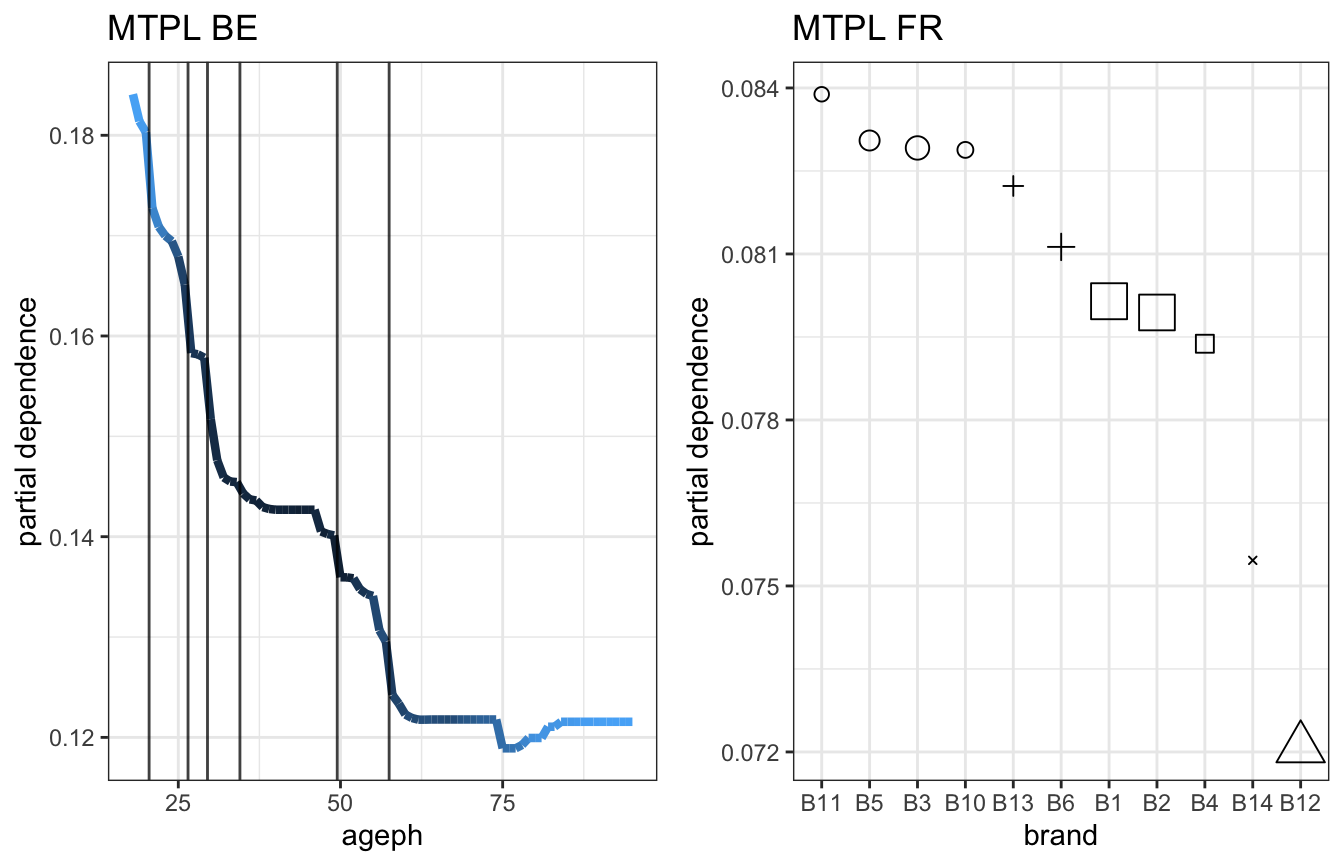
The same can be done for the two interaction effects that we saw earlier:
gridExtra::grid.arrange(fx_vars_be[['ageph_power']] %>% group_pd(ngroups = 3) %>% plot_pd + ggtitle('MTPL BE'), fx_vars_fr[['power_fuel']] %>% group_pd(ngroups = 4) %>% plot_pd + ggtitle('MTPL FR'), ncol = 2)
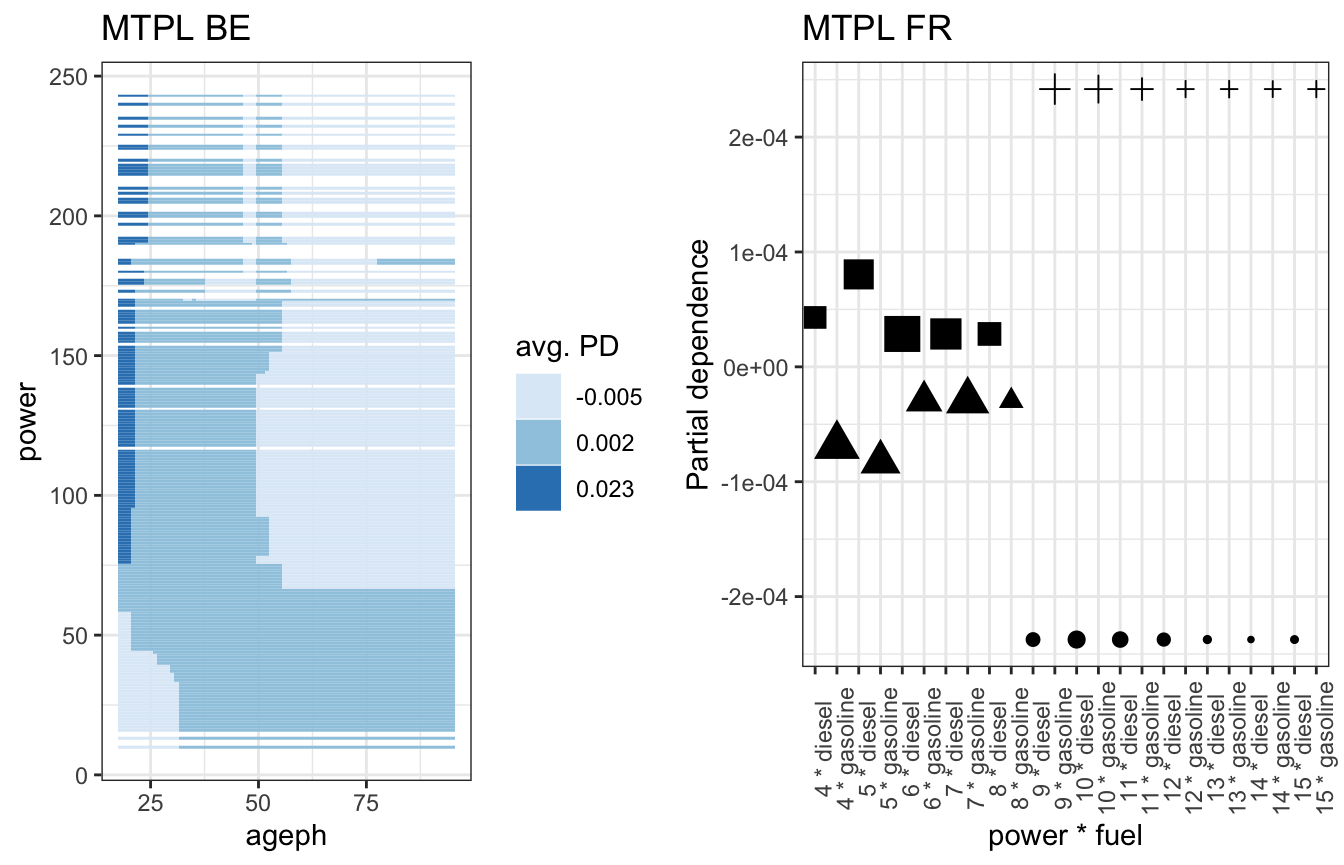
The choice of the value(s) for \(\lambda\) is the most important aspect in the maidrr procedure, as it will determine the level of segmentation in your data. You can tune this parameter yourself or rely on the maidrr::autotune function, which is introduced later. First, we still need to cover the topic of fitting the actual surrogate model.
Helper functions
The function segmentation streamlines the grouping process by making use of several maidrr helper functions:
-
group_pd: groups the effect in an optimal way by making use of theCkmeans.1d.dppackage. -
optimal_ngroups: determines the optimal number of groups for an effect and a specified value of \(\lambda\).
These functions can be used on a stand-alone basis to perform your own tailored analysis. Details on the use of these functions and input requirements are available in the documentation of maidrr.
Fitting a surrogate GLM
Call surrogate(data, par_list) with arguments:
-
data: data frame containing the segmented training data, preferably the output ofmaidrr::segmentation. -
par_list: named list, constructed viaalist(), with additional arguments to be passed on toglm(). Refer to?glmfor all the options, but some common examples are:- formula: object of the class
formulawith a symbolic description of the GLM to be fitted. - family: description of the error distribution and link function to be used in the GLM.
- weights: vector of prior weights to be used in the fitting process.
- offset: a priori known component to be included in the linear predictor during fitting.
- formula: object of the class
It is important to only include featues with at least 2 groups in the formula, the rest is captured by the intercept.
Let’s fit a surrogate Poisson GLM to the segmented BE portfolio with exposure as offset (same specs as GBM):
features_be <- gr_data_be %>% dplyr::select(dplyr::ends_with('_')) %>% dplyr::summarise_all(~dplyr::n_distinct(.) > 1) %>% unlist %>% which %>% names features_be #> [1] "ageph_" "power_" "bm_" "agec_" "coverage_" #> [6] "fuel_" "sex_" "ageph_bm_" "power_bm_" "bm_agec_" #> [11] "ageph_power_" "power_agec_" formula_be <- as.formula(paste('nclaims ~', paste(features_be, collapse = '+'))) formula_be #> nclaims ~ ageph_ + power_ + bm_ + agec_ + coverage_ + fuel_ + #> sex_ + ageph_bm_ + power_bm_ + bm_agec_ + ageph_power_ + #> power_agec_ glm_be <- gr_data_be %>% surrogate(par_list = alist(formula = formula_be, family = poisson(link = 'log'), offset = log(expo))) glm_be #> #> Call: glm(formula = formula_be, family = poisson(link = "log"), data = data, #> offset = log(expo)) #> #> Coefficients: #> (Intercept) ageph_[18, 20] ageph_[21, 26] ageph_[27, 29] #> -2.15011 0.31840 0.17751 0.10415 #> ageph_[30, 34] ageph_[50, 57] ageph_[58, 95] power_[10, 44] #> 0.02506 -0.07009 -0.21766 -0.11401 #> power_[173, 190] power_[191, 243] bm_[10, 10] bm_[11, 13] #> 0.69204 0.90979 0.60588 0.80310 #> bm_[14, 15] bm_[16, 17] bm_[18, 22] bm_[2, 2] #> 0.88277 0.99713 1.00049 0.14921 #> bm_[3, 6] bm_[7, 9] agec_[17, 27] agec_[28, 48] #> 0.30985 0.46746 -0.23962 -1.17518 #> coverage_[2, 3] fuel_{diesel} sex_{female} ageph_bm_1 #> -0.05820 0.14644 0.01365 -0.75437 #> power_bm_1 power_bm_3 bm_agec_1 bm_agec_2 #> -0.02698 0.13837 -8.48634 -0.22720 #> bm_agec_4 ageph_power_2 power_agec_1 power_agec_2 #> 0.05071 0.53276 -9.11280 -0.02316 #> #> Degrees of Freedom: 163209 Total (i.e. Null); 163178 Residual #> Null Deviance: 89870 #> Residual Deviance: 87130 AIC: 124900
Some conclusions can be drawn fast and easily from the fitted GLM coeffients:
- young policyholders are more risky compared to the older ones,
- low powered cars are less risky compared to the high powerded ones,
- the risk is monotonically increasing in the bonus-malus level,
- policyholders driving a new car are more prone to file a claim,
- policyholders with extended coverage above the standard TPL cover are less risky and
- policyholders driving diesel cars are more risky compared to those driving a gasoline car.
Let’s also fit a surrogate Poisson GLM to the segmented FR portfolio with exposure as offset:
features_fr <- gr_data_fr %>% dplyr::select(dplyr::ends_with('_')) %>% dplyr::summarise_all(~dplyr::n_distinct(.) > 1) %>% unlist %>% which %>% names features_fr #> [1] "ageph_" "power_" "bm_" "agec_" "fuel_" "brand_" "region_" formula_fr <- as.formula(paste('nclaims ~', paste(features_fr, collapse = '+'))) formula_fr #> nclaims ~ ageph_ + power_ + bm_ + agec_ + fuel_ + brand_ + region_ glm_fr <- gr_data_fr %>% surrogate(par_list = alist(formula = formula_fr, family = poisson(link = 'log'), offset = log(expo))) glm_fr #> #> Call: glm(formula = formula_fr, family = poisson(link = "log"), data = data, #> offset = log(expo)) #> #> Coefficients: #> (Intercept) ageph_[18, 19] #> -3.00548 0.25085 #> ageph_[20, 20] ageph_[21, 22] #> 0.04277 -0.14930 #> ageph_[23, 34] ageph_[35, 37] #> -0.41031 -0.24509 #> ageph_[38, 40] ageph_[41, 42] #> -0.19183 -0.08053 #> ageph_[43, 43] power_[6, 12] #> -0.01682 0.17128 #> bm_[101, 108] bm_[109, 120] #> 1.89261 1.96181 #> bm_[121, 124] bm_[125, 144] #> 2.36421 2.24518 #> bm_[147, 187] bm_[190, 230] #> 2.38877 3.13180 #> bm_[55, 57] bm_[58, 60] #> 0.46472 0.71702 #> bm_[61, 62] bm_[63, 76] #> 1.56772 0.74622 #> bm_[77, 78] bm_[79, 90] #> 1.78228 0.90464 #> bm_[91, 95] bm_[96, 100] #> 1.16089 1.57041 #> agec_[13, 17] agec_[18, 100] #> -0.21860 -0.50146 #> fuel_{diesel} brand_{B10, B13, B3, B5} #> 0.14005 0.06438 #> brand_{B11} brand_{B12} #> 0.20716 -0.24479 #> brand_{B14} brand_{B6} #> -0.19256 0.03532 #> region_{R11, R22} region_{R25, R52, R53, R54, R72, R94} #> 0.20513 0.08152 #> region_{R31, R42} region_{R41, R91} #> 0.14083 0.01022 #> region_{R73, R83} region_{R74, R93} #> -0.14202 0.23394 #> region_{R82} #> 0.30199 #> #> Degrees of Freedom: 668891 Total (i.e. Null); 668853 Residual #> Null Deviance: 170500 #> Residual Deviance: 161400 AIC: 212200
Global model conclusions can again be drawn from the fitted GLM coefficients. However, let’s turn the focus on explaining predictions for individual observations in the next section.
Explaining the predictions
Call explain(surro, instance, plt = TRUE) with arguments:
-
surro: surrogate GLM object of classglm, preferably the output ofmaidrr::surrogate. -
instance: single row data frame with the instance to be explained. -
plt: boolean whether to return a ggplot (TRUE) or the underlying data (FALSE).-
plt = FALSE: the columnsfit_linkandse_linkcontain the fitted coefficient and standard error on the linear predictor scale. The columnfit_respcontains the coefficient on the response scale after taking the inverse link function, whileupr_confandlwr_confcontain the upper and lower bound of a 95% confidence interval. -
plt = TRUE: shows the coefficient and confidence interval on the response scale. A green dashed line shows the value of the invere link function applied to zero. Features with bars close to this line have a neglegible impact on the predition.
-
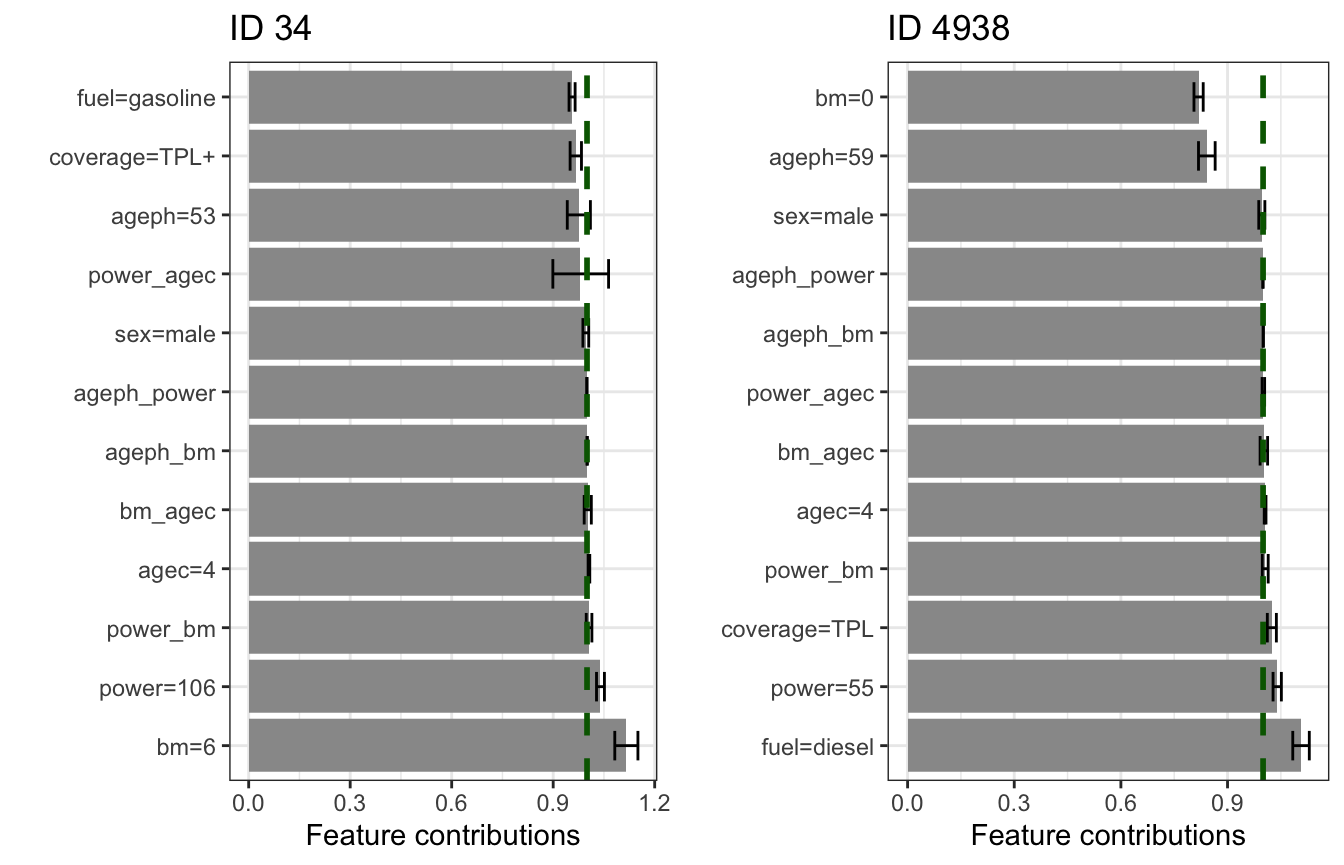
Let’s explain the prediction made by the BE GLM for two policyholders (id 34 and 4938). Notice that the prediction for the former is below the intercept of the GLM, while it is more than doubled for the latter. Why is this the case? The low risk for id 34 is mainly thanks to a low bonus-malus level and high age. Driving a high powered car increases the risk on the other hand. The high risk for id 4938 is mainly due to a high bonus-malus level and young age. Note that these contributions and confidence intervals are shown on the response scale after taking the invere link function of the coefficients. For a Poisson GLM with log-link function this implies applying the exp function on the coefficients, with contributions on the multiplicative response scale and a value of 1 indicating no contribution.
exp(coef(glm_be)['(Intercept)']) #> (Intercept) #> 0.1164716 glm_be %>% predict(newdata = gr_data_be[34, ], type = 'response') / gr_data_be[34, 'expo'] #> 34 #> 0.1364615 glm_be %>% predict(newdata = gr_data_be[4938, ], type = 'response') / gr_data_be[4938, 'expo'] #> 4938 #> 0.1084649 gridExtra::grid.arrange(glm_be %>% explain(instance = gr_data_be[34, ]) + ggtitle('ID 34'), glm_be %>% explain(instance = gr_data_be[4938, ]) + ggtitle('ID 4938'), ncol = 2)
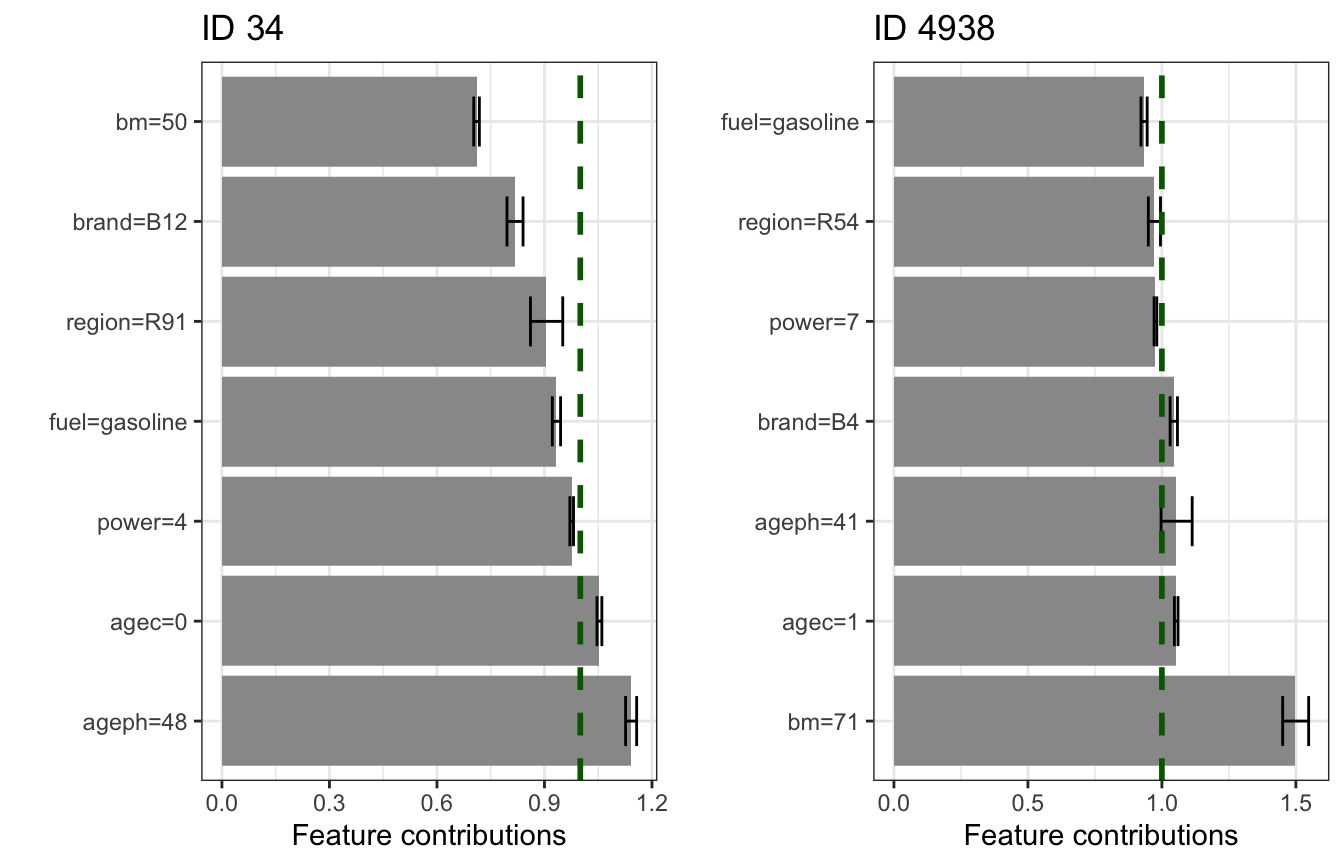
We can follow the same approach for the FR GLM for two policyholders (id 34 and 4938). The prediction for the former is below the GLM intercept, while it is more than doubled for the latter. Why is this the case? The low risk for id 34 is mainly thanks to a low bonus-malus level and driving a car of brand B12 (we have seen this before in the PD effect). The high risk for id 4938 is mainly driven by a high bonus-malus level.
exp(coef(glm_fr)['(Intercept)']) #> (Intercept) #> 0.04951487 glm_fr %>% predict(newdata = gr_data_fr[34, ], type = 'response') / gr_data_fr[34, 'expo'] #> 34 #> 0.03916181 glm_fr %>% predict(newdata = gr_data_fr[4938, ], type = 'response') / gr_data_fr[4938, 'expo'] #> 4938 #> 0.1045311 gridExtra::grid.arrange(glm_fr %>% explain(instance = gr_data_fr[34, ]) + ggtitle('ID 34'), glm_fr %>% explain(instance = gr_data_fr[4938, ]) + ggtitle('ID 4938'), ncol = 2)
These are of course just toy examples to illustrate the functionalty of maidrr, with random segmentation choices (the values for the number of groups or \(\lambda\)). Tuning the value of \(\lambda\) is very important to obtain competitive prediction models. Therefore, we incorporate a function to automate this task for you: maidrr::autotune.
Automated lambda tuning via cross-validation
The maidrr workflow from black box to surrogate via insights %>% segmentation %>% surrogate is highly dependend on the value(s) of \(\lambda\) supplied to maidrr::segmentation. The grouping and selection of features is entirely dependend on \(\lambda\) via the penalized loss function. Any ad-hoc choice is most likely to result in a surrogate which is not really competitive with the original black box model, so it is important to choose the value(s) for \(\lambda\) in an optimal way. To automate this tuning task, maidrr contains the autotune(...) function. This function iterates over a grid of \(\lambda\)’s, calculating cross-validation errors for each grid value, and returns an optimal surrogate GLM.
Call autotune(mfit, data, vars, target, max_ngrps = 15, hcut = 0.75, ignr_intr = NULL, pred_fun = NULL, lambdas = as.vector(outer(seq(1, 10, 0.1), 10^(-7:3))), nfolds = 5, strat_vars = NULL, glm_par = alist(), err_fun = mse, ncores = -1, out_pds = FALSE) with arguments:
-
mfit: fitted model object (e.g., a “gbm” or “randomForest” object) to approximate with a surrogate. -
data: data frame containing the original training data. -
vars: character vector specifying which features ofdatato consider for inclusion in the surrogate. Automatic feature selection will choose the best performing subset of features, possibly with interactions. -
target: string specifying the name of the target (or response) variable to model. -
max_ngrps: integer specifying the maximum number of groups that each feature’s values/levels are allowed to be grouped into. -
hcut: numeric in the range [0,1] specifying the cut-off value for the normalized cumulative H-statistic over all two-way interactions between the features invars. In a nutshell: 1) Friedman’s H-statistic, measuring interaction strength, is calculated for all two-way interactions between the features invars. 2) Interactions are ordered from most to least important and the normalized cumulative sum of the H-statistic is calculated. 3) The minimal set of interactions which exceeds the value ofhcutis retained in the output.-
hcut = 0: only consider the single most important interaction for inclusion in the surrogate. -
hcut = 1: consider all possible two-way interactions for inclusion in the surrogate. -
hcut = -1: do not consider interactions and only use main effects of the features invars.
-
-
ignr_intr: optional character string specifying features to ignore when searching for meaningful interactions to incorporate in the GLM. -
pred_fun: optional prediction function for the model inmfitto calculate feature effects, which should be of the formatfunction(object, newdata) mean(predict(object, newdata, ...)). See the argumentpred.funin thepdp::partialfunction, on whichmaidrrrelies to calculate model insights. This function allows to calculate effects for model classes which are not supported bypdp::partial, see this article. -
lambdas: numeric vector with the possible \(\lambda\) values to explore. The search grid is created automatically viamaidrr::lambda_grid. This grid contains only those values of \(\lambda\) that result in a unique grouping of the full set of features. A seperate grid is generated for main and interaction effects. -
nfolds: integer for the number of folds to use in K-fold cross-validation. -
strat_vars: character (vector) specifying the feature(s) to use for stratified sampling in the creation of the folds. The defaultNULLimplies no stratification is applied. -
glm_par: named list, constructed viaalist(), with additional arguments to be passed on toglm()(see the section onsurrogate). Note however that the argumentformulawill be ignored as the formula is determined automatically by thetargetand the selected features during the tuning process. -
err_fun: error function to calculate the prediction errors on the validation folds. This must be an R function which outputs a single number and takes two vectorsy_predandy_trueas input for the predicted and true target values respectively. An additional input vectorw_caseis allowed to use case weights in the error function. The weights are determined automatically based on theweightsfield supplied toglm_par. The following functions are included already, seemaidrr::err_funfor details:-
mse: mean squared error loss function. -
wgt_mse: weighted mean squared error loss function. -
poi_dev: Poisson deviance loss function.
-
-
ncores: integer specifying the number of cores to use. The defaultncores = -1uses all the available physical cores (not threads). -
out_pds: boolean to indicate whether to add the calculated PD effects for the selected features to the output list.
Let’s autotune the \(\lambda\) parameter on the BE portfolio:
set.seed(5678) tune_be <- gbm_be %>% autotune(data = mtpl_be, vars = gbm_be$var.names, target = 'nclaims', hcut = 0.75, pred_fun = gbm_fun, lambdas = as.vector(outer(seq(1, 10, 0.1), 10^(-7:3))), nfolds = 5, strat_vars = c('nclaims', 'expo'), glm_par = alist(family = poisson(link = 'log'), offset = log(expo)), err_fun = poi_dev, ncores = -1)
The output of maidrr::autotune is a list with the following elements:
-
slct_feat: named vector containing the selected features (names) and the optimal number of groups for each feature (values). -
best_surr: the optimal GLM surrogate, which is fit to all observations indata. The segmented data can be obtained via the$dataattribute of the GLM fit. -
tune_main: the cross-validation results for the main effects as a tidy data frame. The columncv_errcontains the cross-validated error, while the columns1:nfoldscontain the error on the validation folds. -
tune_intr: the cross-validation results for the interaction effects, in the same format astune_main. -
pd_fx: list with the PD effects for the selected features (only present ifout_pds = TRUE).
tune_be #> $slct_feat #> ageph power bm agec coverage fuel #> 8 11 13 6 2 2 #> ageph_bm power_bm bm_agec ageph_power #> 3 6 4 3 #> #> $best_surr #> #> Call: glm(formula = nclaims ~ 1 + ageph_ + power_ + bm_ + agec_ + coverage_ + #> fuel_ + ageph_bm_ + power_bm_ + bm_agec_ + ageph_power_, #> family = poisson(link = "log"), data = data, offset = log(expo)) #> #> Coefficients: #> (Intercept) ageph_[18, 20] ageph_[21, 26] ageph_[27, 29] #> -2.24060 0.31740 0.16065 0.09698 #> ageph_[30, 34] ageph_[50, 55] ageph_[56, 57] ageph_[58, 95] #> 0.02646 -0.05837 -0.07197 -0.20319 #> power_[10, 33] power_[100, 140] power_[141, 170] power_[173, 180] #> -0.18119 0.14301 0.32615 1.59231 #> power_[183, 184] power_[190, 190] power_[191, 243] power_[34, 38] #> -0.33991 -9.24485 1.01483 -0.07334 #> power_[39, 44] power_[67, 99] bm_[1, 1] bm_[10, 10] #> -0.05038 0.11495 0.12608 0.63425 #> bm_[11, 13] bm_[14, 15] bm_[16, 17] bm_[18, 19] #> 0.82718 0.90160 1.01547 1.08043 #> bm_[2, 2] bm_[20, 22] bm_[3, 5] bm_[6, 6] #> 0.18287 0.87123 0.32010 0.38112 #> bm_[7, 7] bm_[8, 9] agec_[0, 1] agec_[17, 18] #> 0.46756 0.51775 0.17576 -0.17843 #> agec_[19, 27] agec_[2, 5] agec_[28, 48] coverage_[2, 3] #> -0.35013 -0.05484 -1.18839 -0.06221 #> fuel_{diesel} ageph_bm_1 ageph_bm_3 power_bm_1 #> 0.15146 -0.75276 0.06298 -0.05216 #> power_bm_3 power_bm_4 power_bm_5 power_bm_6 #> 0.05105 0.07002 0.34149 -0.34556 #> bm_agec_1 bm_agec_2 bm_agec_4 ageph_power_1 #> -8.43938 -0.19868 0.02998 -0.05196 #> ageph_power_3 #> 0.48535 #> #> Degrees of Freedom: 163209 Total (i.e. Null); 163161 Residual #> Null Deviance: 89870 #> Residual Deviance: 86960 AIC: 124700 #> #> $tune_main #> # A tibble: 47 x 16 #> lambda_main ageph power bm agec coverage fuel sex fleet use `1` #> <dbl> <int> <int> <int> <int> <int> <int> <int> <int> <int> <dbl> #> 1 0.0000066 8 11 13 6 2 2 1 1 1 0.534 #> 2 0.0000048 13 12 13 6 2 2 1 1 1 0.534 #> 3 0.0000047 13 12 14 6 2 2 1 1 1 0.534 #> 4 0.00000570 10 11 13 6 2 2 1 1 1 0.534 #> 5 0.0000056 10 12 13 6 2 2 1 1 1 0.534 #> 6 0.00000910 6 11 13 6 1 2 1 1 1 0.534 #> 7 0.0000085 7 11 13 6 1 2 1 1 1 0.534 #> 8 0.00000190 15 15 15 9 2 2 1 2 1 0.534 #> 9 0.0000011 15 15 15 9 2 2 2 2 1 0.534 #> 10 0.00000210 15 14 15 9 2 2 1 2 1 0.534 #> # … with 37 more rows, and 5 more variables: `2` <dbl>, `3` <dbl>, `4` <dbl>, #> # `5` <dbl>, cv_err <dbl> #> #> $tune_intr #> # A tibble: 44 x 11 #> lambda_intr ageph_bm power_bm bm_agec ageph_power `1` `2` `3` `4` #> <dbl> <int> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> #> 1 0.00004 3 6 4 3 0.534 0.533 0.532 0.534 #> 2 0.000024 5 7 5 4 0.534 0.533 0.533 0.533 #> 3 0.00002 5 9 5 5 0.534 0.533 0.533 0.534 #> 4 0.00003 5 6 5 4 0.534 0.533 0.533 0.533 #> 5 0.000022 5 9 5 4 0.534 0.533 0.533 0.534 #> 6 0.000039 3 6 5 3 0.534 0.533 0.533 0.534 #> 7 0.000036 3 6 5 4 0.534 0.533 0.533 0.533 #> 8 0.000019 5 9 6 5 0.534 0.533 0.533 0.534 #> 9 0.00005 3 6 3 3 0.534 0.533 0.533 0.534 #> 10 0.000051 3 6 3 2 0.534 0.533 0.533 0.534 #> # … with 34 more rows, and 2 more variables: `5` <dbl>, cv_err <dbl>
These are the optimal groupings obtained for the effects that were shown earlier in this vignette:
gridExtra::grid.arrange(fx_vars_be[['ageph']] %>% group_pd(ngroups = tune_be$slct_feat['ageph']) %>% plot_pd + ggtitle('MTPL BE'), fx_vars_be[['ageph_power']] %>% group_pd(ngroups = tune_be$slct_feat['ageph_power']) %>% plot_pd + ggtitle('MTPL BE'), ncol = 2)